Scalable Data Pre-processing Infrastructure

Massive data without bias
Akros Technologies has been receiving huge amounts of hedge fund-level data from a variety of data vendors. We directly receive and process over 100 TB+ data, including 100k+ macro data starting in 1910, fundamental data from 1950 including point-in-time data, transcripts by each speaker, and even quote data by each market maker.
However, no matter how good data is received from a suitable data vendor, the data is not immediately pre-processed to be ready for an analytical simulation. Adjusting survivorship bias and look-ahead bias requires quite a bit of computation. And data from vendors are also often modified in real-time and so a real-time data processing system is required if possible.
The goal of Hippo, which is both our data pre-processing system and data processing API, is to provide quantitative researchers working at Akros and the Causal AI systems that we have built, Alpha Intelligence & Beta Intelligence, with unbiased data ready for a simulation.
Hippo V1: Single REST API Async Server
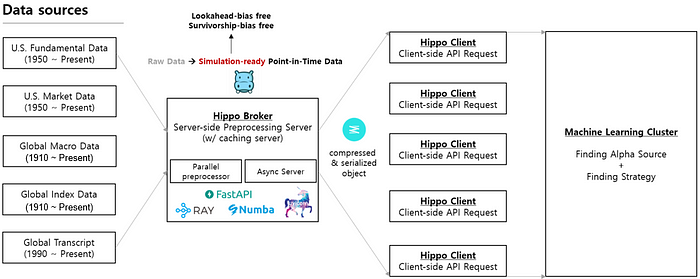
Our first approach was to build an asynchronous REST API server to preprocess data and deliver a compressed binary object to each client in our machine learning cluster. This architecture was quite easy to build and was also sufficient when our computing resource was capped at around 50 cores.
Initially, when human-led alpha research was dominating and no more than 50 cores were being utilized, a single hippo broker server with 16 cores was sufficient. The problem occurred when our Causal AI such as Alpha Intelligence started to conduct alpha research automatically with its dedicated simulation. We increased our computing resources from 50 to 200 cores, and a problem arose immediately.
Hippo V2: MQ + Auto-scaling Server in Kubernetes

As soon as we recognized this problem, we started a project entailing Hippo V2 update. The key to this project was scalability. Distributed data storage such as GlusterFS & Ceph and a new NAS were introduced to increase storage and process data more efficiently. We were deploying our new multi-node Kubernetes through RKE2 out of minikube-based single node cluster at the time, and so it was adequate timing for us to start this new project.
The problem was that distributing jobs to multi POD was not possible through Hippo V1 architecture because the pre-processing server accepts requests from multiple clients even though jobs are overloading. Load balancing with worker pools might be okay but once the enormous jobs are already registered, it’s too late to scale unless existing workers cancel the overloaded jobs and re-register them. But there is some kind of a niche way to solve this problem.
It was inevitable for us to deploy a new message queue service before distributing the jobs. Message queue service is now an intermediary broker that efficiently distributes the jobs across multiple, auto-scaled pods.
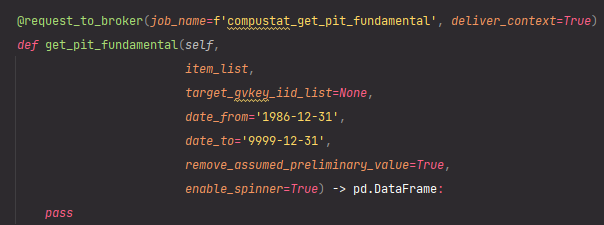
Now Hippo V2 client dumps all information related to executing jobs and delivers them to the message queue service, and the broker distributes each job to the pre-processing servers.
During this process, a backup DB for the main DB is constantly updated. That is, a backup service is created that periodically uploads dumped files of the existing DB to an external S3 service. In fact, since the pre-processing server is stored in the form of a container image, it can be easily backed up at any time, in contrast to raw data, which is not so convenient to deal with.
Watchdog: POD Recovery Plan
There was another problem when we were deploying pre-processing server as a pod. While some jobs required less RAM, others simply required more. A limitation of resources led to the sudden death of the operating POD, Resource limitation optimization is an important task because the maximum number of pre-processing is determined by this limitation as a total resource is fixed. Too much RAM will reduce the available number of scaling and too little RAM will increase the probability of pod termination.
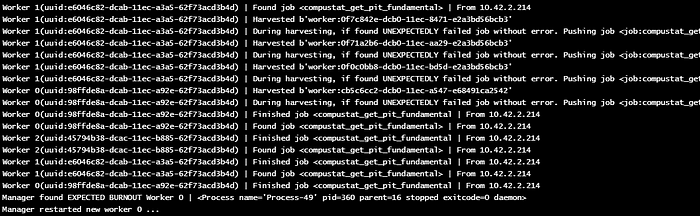
This is important because the broker which distributes jobs cannot acknowledge whether or not the job has failed due to resource limitation issues, and so it would just wait forever.
This is the precise reason why we needed a watchdog that oversees the failure of the job and reports the status of POD.

Now That’s It
Deploying a new service is quite easy thanks to Akros Resource Manager & Service Manager.
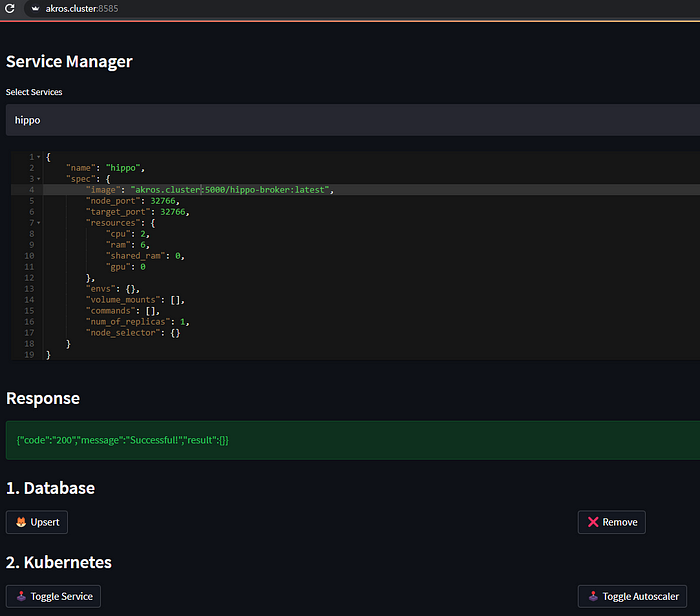
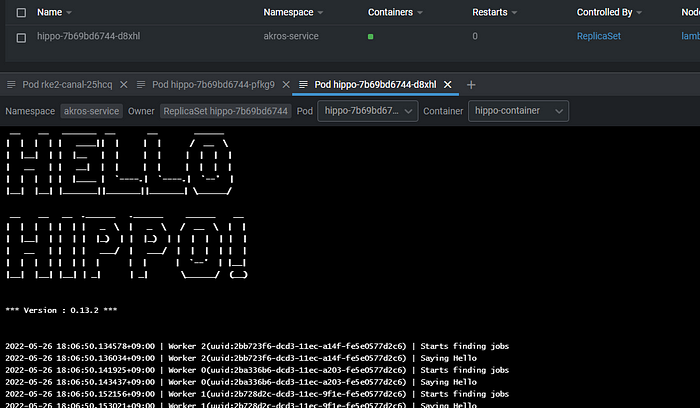
The watchdog is also working as expected. Health check & worker status notice by the watchdog shows the number of available workers. If the number of workers is not deemed sufficient by monitoring CPU status, then the auto-scaler automatically increases the number of deployed workers.
Yay! 1000+ parallel research by AI is now affordable

Want to use our super-clean scalable data infrastructure?
Join Akros Team. We are disrupting investment management.